Karpenter is open-source , highly efficient and reliable cluster autoscaler, designed specially for AWS EKS. It is just-in-time EC2 provisioning tool for pending PODs which scale up/down the nodes based on the requirements. It is no matter the de-facto standard for auto scaling. Karpenter does the auto-scaling purely based on the infra stats along with configuration parameters.
However, there are cases where human intervention is required to control the scaling mechanism to save further cost.
I often observed the cases wherein, Karpenter scales the node due to some spike in CPU / memory but that sometime is just a temporary one rather than the real workload. Real workload is what when ( for example : DB transactions increases, SQL query takes more time to execute OR high processing on tenants due to batch processing of large transactions). In such cases, it makes sense to increase the infrastructure capacity to suffice the additional resource constraint from the workload but if it is false-positive then also scale up happens and nodes gets added. To deal with such real use cases and avoid false positives , the full-proof solution would be to introduce human -Approval gate which would be more mindful and cautious decision whether to add/delete nodes in EKS or not.
Karpenter Sentinel adds a mandatory human sign-off to kubernetes scale-up events on AWS EKS . As we all know, Karpenter provisions new nodes automatically within seconds of detecting pending PODS which is no doubt useful and makes sense for lower environments like Dev/QA. but problematic in higher environments where unchecked scaling means unexpected cost , capacity management drift and nearly no visibility in operational area .
What is does
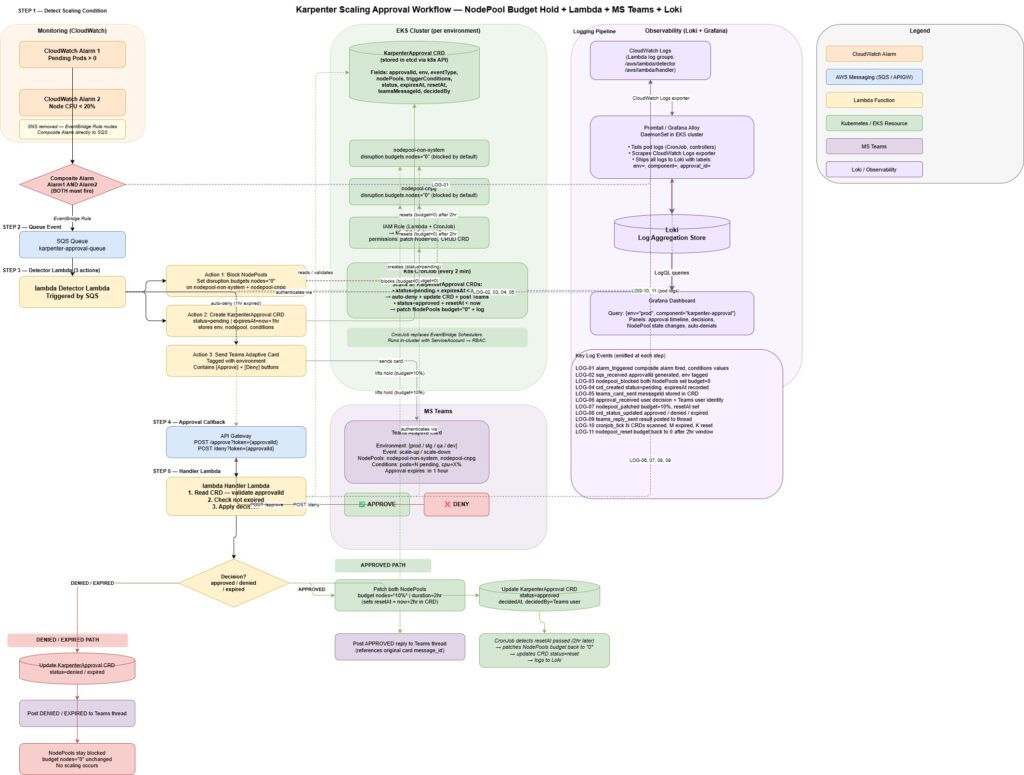
When node CPU / Memory OR data transfer usage crosses 80 % and there is genuinely pending workload POD, the system pauses the provisioning and notifies the on-call person/operator via MS Teams card. The card shows current cluster’s stats and presents two button : Approve OR Deny along with metrics details on why this scaling request has been made. Unless and until on-call person/operator clicks the either of those buttons , Karpenter can not provision the new node. How this has happened – A Kubernetes Validating Admission webhook grabs every NodeClaim CREATE request and blocks it. If no action is taken within 30 min. the request expires and blocking continues.
How Enforcement / Prosecution works – The Novelty part
The human approval gate is built on a Kubernetes Custom resource definitions. CRDs maintains the state. To maintain and manage the lifecycle of the CRDs and to check alarms , a JAVA cronjob controller is built . This controller runs every 2 minutes. The MS Team buttons click events are handled by the Lambda function behind the API gateway. This lambda function also handles the CRDs state transition. The webhook is the real enforcer, it reads the CRD request on every NodeClaim request and denies the request which is not explicitly approved.
CRDs are the real sole gate. No need to change / modify any YAML file OR patch the specs directly on live objects. Scale-down is fully automatic – no need of any approval. When the new node is not needed , Karpenter consolidates the node as per policy / configuration and cluster is back to baseline on its own .
Below is the conceptual depiction on how things flow.
This is truly a cost saver and huge success . Cheers !!!